





.avif)

Building a meeting bot from scratch usually means juggling SDKs, app reviews, raw media handling, and storage for each meeting platform (Zoom, Google Meet, Microsoft Teams, etc.). In this tutorial, I’ll skip that complexity. Using a single, platform-agnostic API, I’ll show you how to create a bot that can:
- Join meetings on Zoom, Google Meet, Microsoft Teams, and more
- Stream transcripts, video, and audio in real time
- Deliver post-meeting recordings
- Notify your backend of events via webhooks
By the end, you’ll have a production-ready meeting bot that feeds conversation data to your app and can even send data back into live meetings.
What is a meeting recording bot?
Before I dive into how to build a meeting bot, let’s take a moment to cover what a meeting bot is. A meeting bot is a way for your app to capture data from meetings. It appears in the meeting like a participant does, taking up another participant tile.
Meeting bots can join meetings on Zoom, Google Meet, Microsoft Teams, or other platforms, capture audio/video for real-time or post-meeting delivery, and produce transcripts while the meeting is happening or after it ends. People often use “meeting bot,” “meeting recording bot,” and “bot recording” interchangeably. In this article, we'll also use these terms interchangeably.
Beyond using an API to send a meeting bot to a meeting, there are other ways to get meeting data: first-party APIs and desktop recording SDKs. This guide focuses on adding a bot to a meeting with the Recall.ai Meeting Bot API because it combines simplicity, reliability, and speed, and allows users to send data into the meeting. If you want to build a meeting bot from scratch, check out our posts on how to build a Zoom bot, how to build a Google Meet bot, and how to build a Microsoft Teams bot.
Prerequisites to building a meeting bot
You need three things before you write a line of code:
- A Recall.ai account + API key, you can sign up for free
-
A meeting URL (Zoom, Google Meet, or Microsoft Teams).
- During development, it’s fine to paste a URL directly into your request. But in production, you may not want to rely on your end users manually copying and pasting links every time they want a bot to join their meeting. That’s where a calendar integration helps: once a user has connected their calendar, your app can automatically detect upcoming meetings and pass the correct URL to the bot without any manual input from the user.
-
A backend that can receive webhooks. During development, expose your local server using ngrok (or any other tunneling tool) so Recall.ai can reach it. With a free ngrok account, you can claim one static domain, which is a persistent subdomain that won’t change every time you start ngrok. Set the
NGROK_BASEin the example code to your static domain, which will look something likehttps://random-subdomain-here.ngrok-free.app.
For this tutorial I used Python + FastAPI in the examples, but the API is language-agnostic. If you prefer TypeScript, you can check out How to get recordings from Zoom or How to get transcripts from Zoom, which go over how to add a Zoom bot in TypeScript.
Step 1: Create a bot
The first step is to tell Recall.ai which meeting to join and what to deliver back. I wrote a simple server that calls Create Bot with a meeting_url and a recording_config that specifies how to capture and deliver the transcripts, audio, video, and participant events. Because I opted to add real-time data, I also registered where Recall.ai should push that data. I used a webhook URL to receive transcript and participant events, and a WebSocket to receive raw media frames.
//@title app/pythonHowToBuildABot.py — call create bot endpoint (/start)
import os, json, base64
from collections import defaultdict
import httpx
from fastapi import FastAPI, Request, WebSocket, WebSocketDisconnect
from fastapi.responses import JSONResponse
import uvicorn
from starlette.websockets import WebSocketDisconnect, WebSocketState
API = f"https://{RECALL_REGION}.recall.ai/api/v1"
H = {"Authorization": f"Token {RECALL_API_KEY}", "Content-Type": "application/json"}
@app.post("/start")
async def start(payload: dict):
assert http is not None, "HTTP client not initialized"
meeting_url = payload["meeting_url"]
display_name = payload.get("display_name", "Recall Bot")
platform = payload.get("platform")
meeting_pw = payload.get("meeting_password")
ws_url = payload.get("ws_url") # e.g., f"{NGROK_BASE}/ws/rt?token={WS_TOKEN}"
realtime_video = payload.get("realtime_video") # None | "png" | "h264"
endpoints = [{
"type": "webhook",
"url": f"{NGROK_BASE}/wh",
"events": [
"transcript.data",
"participant_events.join","participant_events.leave","participant_events.update",
"participant_events.speech_on","participant_events.speech_off",
"participant_events.webcam_on","participant_events.webcam_off",
"participant_events.screenshare_on","participant_events.screenshare_off",
"participant_events.chat_message"
],
}]
if ws_url:
# MEDIA ONLY on WS
ws_events = ["audio_mixed_raw.data"]
if realtime_video == "png": ws_events.append("video_separate_png.data")
if realtime_video == "h264": ws_events.append("video_separate_h264.data")
endpoints.append({"type": "websocket", "url": ws_url, "events": ws_events})
recording_config = {
"transcript": {"provider": {"recallai_streaming": {
"language_code": "en", "filter_profanity": False, "mode": "prioritize_low_latency"
}}},
"participant_events": {},
"meeting_metadata": {},
"start_recording_on": payload.get("start_recording_on", "participant_join"),
"realtime_endpoints": endpoints,
"audio_mixed_raw": {},
}
# PNG only — add variant to be safe (helps separate video reliability)
if realtime_video == "png":
recording_config.update({
"video_separate_png": {},
"video_mixed_layout": "gallery_view_v2",
"variant": {"zoom": "web_4_core", "google_meet": "web_4_core", "microsoft_teams": "web_4_core"}
})
elif realtime_video == "h264":
recording_config.update({
"video_separate_h264": {},
"video_mixed_layout": "gallery_view_v2",
"variant": {"zoom": "web_4_core", "google_meet": "web_4_core", "microsoft_teams": "web_4_core"}
})
body = {"meeting_url": meeting_url, "bot_name": display_name, "recording_config": recording_config}
if platform: body["platform"] = platform
if meeting_pw: body["meeting_password"] = meeting_pw
# Helpful to confirm subscriptions quickly
log("[start] recording_config =", json.dumps(recording_config, separators=(",", ":"), ensure_ascii=False)[:2000])
try:
r = await http.post(f"{API}/bot", headers=H, json=body)
r.raise_for_status()
except httpx.HTTPStatusError as e:
return JSONResponse(
{"ok": False, "status": e.response.status_code, "url": str(e.request.url), "body": e.response.text},
status_code=502
)
bot = r.json()
bot_id = bot.get("id") or bot.get("bot_id") or bot.get("uuid") or (bot.get("data") or {}).get("id")
return {"bot_id": bot_id, "webhook": f"{NGROK_BASE}/wh", "websocket": ws_url or None, "video": realtime_video or "none"}
The API responds with a bot_id. Copy it. Keep it. You’ll need it to retrieve artifacts later.
For an exhaustive example cURL request, check out the appendix. If you want your bot to display a video or image, or play audio into the meeting, you can configure output settings in the same recording_config. I’ll cover that later in the Output Media section.
One practical note: ad hoc meetings often start without a scheduled calendar event. That’s fine. Bots can join after a meeting has begun. Simply call the Create Bot endpoint with the meeting URL and a bot will join the meeting and begin recording.
//@title Create bot cURL request
# Create bot (uses recallai_streaming as the transcription provider; expands $NGROK_BASE for your webhook)
curl -X POST "https://$RECALL_REGION.recall.ai/api/v1/bot" \
-H "authorization: Token $RECALL_API_KEY" \
-H "content-type: application/json" \
-d '{
"meeting_url": "PASTE_YOUR_MEETING_LINK",
"recording_config": {
"transcript": { "provider": { "recallai_streaming": { "language_code": "en" } } },
"video_mixed_mp4": {},
"audio_mixed_mp3": {},
"realtime_endpoints": [
{
"type": "webhook",
"url": "'"$NGROK_BASE"'/wh",
"events": ["transcript.data", "bot.status_change"]
}
]
}
}'
Step 2: Subscribe to real-time events
Once the bot is in the meeting, Recall.ai can send events to your app. The meeting bot I built gets all of the most commonly requested real-time data: transcripts, participant events (join, leave, mute, camera on/off, etc.), and bot status changes.
I’ll first focus on bot status changes. Bot status changes tell your app what state the bot is in (such as in_waiting_room, call_ended, etc.). Here I’ll subscribe to bot.status_change webhook events to figure out when a bot has left the meeting so that I can fetch the post-meeting artifacts. To subscribe to these events, I’ll go to the Recall.ai dashboard, select Webhooks on the left side, click Add Endpoint, paste the URL that I’ll be using to listen for events (the ngrok domain in my case), and select bot.status_change under bot in Subscribe to events. Once I’ve done that, I’ll get a webhook event from Recall.ai whenever a bot status change occurs. I recommend listening for the bot.done event, which indicates that the bot is done and the artifacts are ready for download.

How to get real-time transcripts and participant events
I’ll also receive transcripts, participant events, etc., in real time via webhook events.
Within the recording_config from step 1, I had specified recallai_streaming as my transcription provider — this allows me to receive a post-meeting transcript. In order to get real-time transcripts, I also need to subscribe to a real-time endpoint for transcripts like this:
"realtime_endpoints": [
{
"type": "webhook",
"url": "'"$NGROK_BASE"'/wh",
"events": [
"transcript.data",
]
}
]
To receive a real-time transcript, I listen for transcript.data events. In order to receive and respond appropriately to the transcript events, I need a minimalist webhook handler that does three things: parse JSON, branch by event, and ack fast. I put together a small webhook handler:
//@title app/pythonHowToBuildABot.py — /wh (excerpt)
from fastapi import Request
from fastapi.responses import JSONResponse
@app.post("/wh")
async def wh(req: Request):
try:
p = await req.json()
except Exception:
raw = await req.body()
print("[wh] non-JSON payload:", raw[:200])
return JSONResponse({"ok": False, "error": "bad json"}, status_code=400)
ev = p.get("event") or p.get("type", "")
dat = p.get("data") or p.get("payload") or {}
dd = dat.get("data") or {}
if ev == "transcript.data":
words = dd.get("words") or []
text = " ".join((w.get("text","") for w in words)) or dd.get("text","") or ""
who = (dd.get("participant") or {}).get("name")
print(f"[wh] transcript speaker={who} text={text}")
elif ev == "bot.status_change":
code = dd.get("code")
print(f"[wh] bot.status_change code={code}")
if code == "bot.done":
# Artifacts are ready via Retrieve Bot.
pass
# TODO: handle participant_events.* similarly (join/leave/update/chat)
# Return quickly (2xx) to avoid retries; enqueue heavy work in the background.
return JSONResponse({"ok": True})
You might have noticed the comment in my webhook handler to return quickly. Because Recall.ai may retry if my server doesn’t acknowledge quickly, I return a 2xx response immediately, queue work in the background, and make writes idempotent so duplicates don’t cause problems. For more on retries and idempotency patterns, see the appendix.
For a full look at the options for transcript and participant events, check out the docs or take a look at the GitHub repo for the config.
How to get real-time audio and video
Webhooks are perfect for structured events like transcripts, participant updates, and bot status changes. But because I want real-time video and audio as well, I need to establish a WebSocket connection.
Once I open the WebSocket connection, Recall.ai streams binary-encoded audio and video data directly to my server in real time. Since audio and video frames arrive many times per second, the stream generally runs at a higher frequency and bandwidth than webhook events. This makes real-time streams received via WebSockets a better fit for use cases like observer rooms or deepfake detection, which all require real-time analysis. I put together a minimal WebSocket handler below to subscribe and start decoding those events:
//@title app/pythonHowToBuildABot.py — /ws/rt (excerpt)
import json, base64
from fastapi import WebSocket, WebSocketDisconnect
@app.websocket("/ws/rt")
async def ws_rt(ws: WebSocket):
await ws.accept()
try:
while True:
try:
txt = await ws.receive_text()
except WebSocketDisconnect:
break
try:
e = json.loads(txt)
except Exception:
print("[ws] bad-json")
continue
ev = e.get("event")
d = e.get("data") or {}
dd = d.get("data") or {}
buf = dd.get("buffer")
if ev == "audio_mixed_raw.data" and buf:
n = len(base64.b64decode(buf))
print(f"[ws] audio {(n//32)}ms {n/1024:.1f}KB") # 16kHz mono s16le → 32 bytes ≈ 1ms
elif ev == "video_separate_png.data" and buf:
raw = base64.b64decode(buf)
who = (dd.get("participant") or {}).get("name")
print(f"[ws] png {len(raw)/1024:.1f}KB {who}")
elif ev == "video_separate_h264.data" and buf:
n = len(base64.b64decode(buf))
who = (dd.get("participant") or {}).get("name")
print(f"[ws] h264 {n/1024:.1f}KB {who}")
elif ev == "transcript.data":
words = dd.get("words") or []
text = " ".join((w.get("text","") for w in words)) or dd.get("text","") or ""
who = (dd.get("participant") or {}).get("name")
print(f"[ws] transcript {who}: {text}")
else:
print("[ws] event", ev)
finally:
print("[ws] disconnected")
With both the webhook registered and WebSocket connection established, I’ll start seeing events flow into my terminal. Transcript lines will print out with speaker names, audio events will log their frame sizes and timestamps, and I’ll even see per-participant PNG or H.264 video frames being received in real time. So at this point, my meeting bot is sending my app all data in real time.
Step 3: Retrieve recordings and transcripts post-meeting
As long as the bot is in the meeting, artifacts are still being generated. In order to fetch the artifacts generated by the meeting, the bot must no longer be in the meeting and the bot status must be bot.done. At that point, any processing has finished and I pull all of the data collected about the meeting with a single call to the Retrieve Bot endpoint:
//@title app/pythonHowToBuildABot.py — /retrieve/{bot_id} (excerpt)
@app.get("/retrieve/{bot_id}")
async def retrieve(bot_id: str):
r = await http.get(f"{API}/bot/{bot_id}", headers=H)
r.raise_for_status()
return r.json()
The response generated when I hit this endpoint includes the download URLs for the audio, video, transcript, metadata, and participant events that I specified in my recording_config. The response also includes meeting chat data and meeting metadata like start/end time.
To get the download_urls, I read the media_shortcuts field in the JSON response for the recording. Think of media_shortcuts as a little bundle of ready-to-use links for the most common outputs (final transcript JSON, mixed MP4 video, participant events, metadata, and mixed MP3 audio) already scoped to that recording. The URLs are pre-signed links to the artifacts stored in S3. Don’t cache them. Instead, store the bot_id and fetch fresh links whenever you need to play or download.
Here's an abbreviated example of the JSON response you might get from the Retrieve Bot endpoint:
{
"id": "[BOT_ID]",
"status": { "code": "bot.done" },
"recordings": [
{
"id": "[RECORDING_ID]",
"media_shortcuts": {
"transcript": { "data": { "download_url": "https://..." } },
"video_mixed": { "data": { "download_url": "https://..." } },
"audio_mixed": { "data": { "download_url": "https://..." } }
}
}
]
}
A few things to note:
- Keys only appear for assets you enabled in your
recording_config. - Meetings can produce multiple recordings (see the appendix to learn more). If your bot has multiple recordings, iterate through them.
As a quick check, I open each media_shortcuts download_url in a browser to verify the transcript and recordings.
Once you’ve verified the download_urls, you can move on to handling them programmatically. For a JSON parsing example that extracts download_urls, see the appendix. If you’re after less-common artifacts that won’t be found in the media_shortcuts, the appendix covers those too.
For a deeper walkthrough that focuses only on specific artifacts, see How to get transcripts from Zoom and How to get recordings from Zoom.
How to store meeting artifacts
Now that I’ve got the meeting artifacts, the next step is figuring out how and where to store them. For this tutorial, I’m using Recall.ai’s Storage and Playback because it’s by far the simplest option and saves me from having to manage my own storage setup. Plus, it keeps everything easily accessible whenever I need it.
Storage & Playback (default, recommended)
Since I’ve opted to use Recall.ai’s Storage and Playback option, I don’t need to do anything in order to store my recordings and transcripts. For this tutorial, I keep the bot.id in memory. In production, persist it (e.g., add a recording field/table) so you can fetch fresh links on demand. Any time I need the transcript JSON or MP4/MP3, I call the Retrieve Bot endpoint with the bot.id and read the media_shortcuts on each recording. The links in media_shortcuts are pre-signed and short-lived by design, so don’t cache them. Instead, fetch fresh URLs when you need to play or download. If I needed recordings that were not included in media_shortcuts I could also store the recording.id and hit the Retrieve Recording endpoint to access less common media like speaker-separated audio.
Alternative: Zero-data retention
If your subprocessor policy requires that Recall.ai never retains data, set the retention field in recording_config to null for zero-data retention. Recall.ai won’t store anything, so you’ll need to stream and save the data yourself.
If, however, your policy allows Recall.ai to hold data briefly, you can listen for the bot.done event, grab the artifacts from media_shortcuts right away by hitting the Retrieve Bot endpoint, and then expire the data. This gives you a short window to download everything before it’s permanently deleted.
Be aware: once you delete/expire the data from Recall.ai, if you lose your copy, the data is gone.
For more tips on fetching and storing data, see the appendix.
Step 4: Process the data from your bot recording
I’ve gone over how to get post-meeting artifacts (via media_shortcuts). The next step is to turn the data you’ve collected into things users actually use (readable notes, action items, search, and shareable links) without locking you into a particular stack or storage choice. If you want to go further, you can also layer in context about who spoke, who shared screens, and what was shown.
I’ll do four small passes (and toss in an optional fifth for fun):
- Load & flatten the transcript into consistent segments
- Shape segments into readable paragraphs (speaker-grouped)
- Summarize & extract actionable items (LLM-agnostic hook)
- Search & deliver results where your users live (Slack/email/your UI)
- (Optional) Enrich with participant, audio, and video context
Below are tight Python excerpts. Full helpers live in the appendix.
4.1 Prepare the transcript for processing
Recall.ai already provides transcripts in a normalized, speaker-grouped format for both real-time and post-meeting use. Each transcript entry includes a participant object (with speaker metadata) and a list of words, each containing text and timestamps.
Before you group or summarize, flatten this structure into a simpler list of {speaker, start_ms, end_ms, text} objects. This keeps downstream steps, like paragraph grouping, summarization, and timestamp linking, clean and consistent.
Here’s a quick helper that loads the transcript JSON and flattens it into that shape:
//@title app/step4.py
def to_segments(transcript_json: Any) -> List[Dict[str, Any]]:
"""
Convert a normalized Recall.ai transcript into a flat list of text segments.
Input shape (guaranteed by Recall.ai):
[
{
"participant": { "name": "Alice", ... },
"words": [
{ "text": "hello", "start_timestamp": {"relative": 0.0}, "end_timestamp": {"relative": 0.4} },
{ "text": "everyone", "start_timestamp": {"relative": 0.4}, "end_timestamp": {"relative": 1.0} }
]
},
...
]
Output shape (used by downstream helpers):
[
{ "speaker": "Alice", "start_ms": 0, "end_ms": 1000, "text": "hello everyone" },
...
]
"""
# If the payload isn't the expected list (e.g., empty or malformed), return nothing.
if not isinstance(transcript_json, list):
return []
out: List[Dict[str, Any]] = []
# Each entry represents one speaker turn (a participant + their spoken words)
for entry in transcript_json:
words = (entry or {}).get("words") or []
if not words or not isinstance(words, list):
continue # skip empty or invalid word lists
# Extract relative timestamps (in seconds) and convert to milliseconds.
# We use the first word's start and last word's end to bound the segment.
try:
start_rel = float(words[0]["start_timestamp"]["relative"])
end_rel = float(words[-1]["end_timestamp"]["relative"])
except (KeyError, TypeError, ValueError):
# If timestamps are missing or malformed, skip this segment.
continue
# Join all word texts into a single line of readable text.
text = " ".join((str(w.get("text", "")).strip() for w in words)).strip()
if not text:
continue
# Use the participant's display name if available.
speaker = ((entry.get("participant") or {}).get("name")) or None
# Append the normalized segment.
out.append({
"speaker": speaker,
"start_ms": int(start_rel * 1000),
"end_ms": int(end_rel * 1000),
"text": text
})
return out
4.2 Make the transcript readable

Once you’ve flattened the transcript, you’ll group adjacent segments by speaker with a small time gap. Grouping adjacent segments makes transcripts readable because, while transcripts often arrive as word bursts, users tend to read paragraphs.
//@title app/step4.py - paragraphs (excerpt)
from typing import List, Dict, Any
def to_paragraphs(segments: List[Dict[str, Any]], gap_ms: int = 1200) -> List[Dict[str, Any]]:
"""
Merge consecutive segments if the speaker stays the same and the gap < gap_ms.
"""
out: List[Dict[str, Any]] = []
cur: Dict[str, Any] | None = None
for s in sorted(segments, key=lambda x: x["start_ms"]):
new_block = (
cur is None or
s.get("speaker") != cur.get("speaker") or
s["start_ms"] - cur["end_ms"] > gap_ms
)
if new_block:
if cur: out.append(cur)
cur = dict(s)
else:
cur["end_ms"] = max(cur["end_ms"], s["end_ms"])
cur["text"] = (cur["text"] + " " + s["text"]).strip()
if cur: out.append(cur)
return out
4.3 Turn conversation into summaries and action items (LLM-agnostic)
Now that you have clean paragraphs, you can feed them into any LLM or summarization model to produce structured notes.

Keeping this step model-agnostic by using a generate() that you control lets you try different providers without rewriting your pipeline to find the best fit for your use case.
Ask for structured JSON with timestamp anchors so you can link users back to the moment when something was said.
//@title app/step4.py - summarize + actions (excerpt)
import json
from typing import Callable, Dict, Any, List
def build_summary_and_actions(
paragraphs: List[Dict[str, Any]],
generate: Callable[[str], str], # plug in your LLM of choice
max_chars: int = 15000
) -> Dict[str, Any]:
"""
generate(prompt) -> stringified JSON with keys:
{
"summary": str,
"highlights": [{"title": str, "start_ms": int, "end_ms": int, "quote": str}],
"action_items": [{"title": str, "owner": str|null, "due_date": str|null, "confidence": float, "evidence_ms": int}]
}
"""
def fmt_time(ms: int) -> str:
s = max(0, ms // 1000); return f"{s//60:02d}:{s%60:02d}"
lines = []
for p in paragraphs:
speaker = p.get("speaker") or "Speaker"
ts = fmt_time(p.get("start_ms", 0))
lines.append(f"[{ts}] {speaker}: {p['text']}")
text = "\n".join(lines)[:max_chars]
prompt = f"""
You are turning a meeting transcript into structured, linkable notes.
Return STRICT JSON with keys: summary, highlights[], action_items[].
- highlights[]: title, start_ms, end_ms, quote (verbatim from the transcript)
- action_items[]: title, owner (email or null), due_date (YYYY-MM-DD or null), confidence (0..1), evidence_ms
Only use information present in the transcript below.
Transcript:
{text}
""".strip()
raw = generate(prompt)
try:
data = json.loads(raw)
data.setdefault("summary", "")
data.setdefault("highlights", [])
data.setdefault("action_items", [])
return data
except Exception:
return {"summary": "", "highlights": [], "action_items": []}
4.4 Help users find and share what matters
Once you’ve summarized the meeting, you might want to allow users to explore or share insights.
Even a simple keyword search becomes powerful when each result links straight to the right moment in the recording.
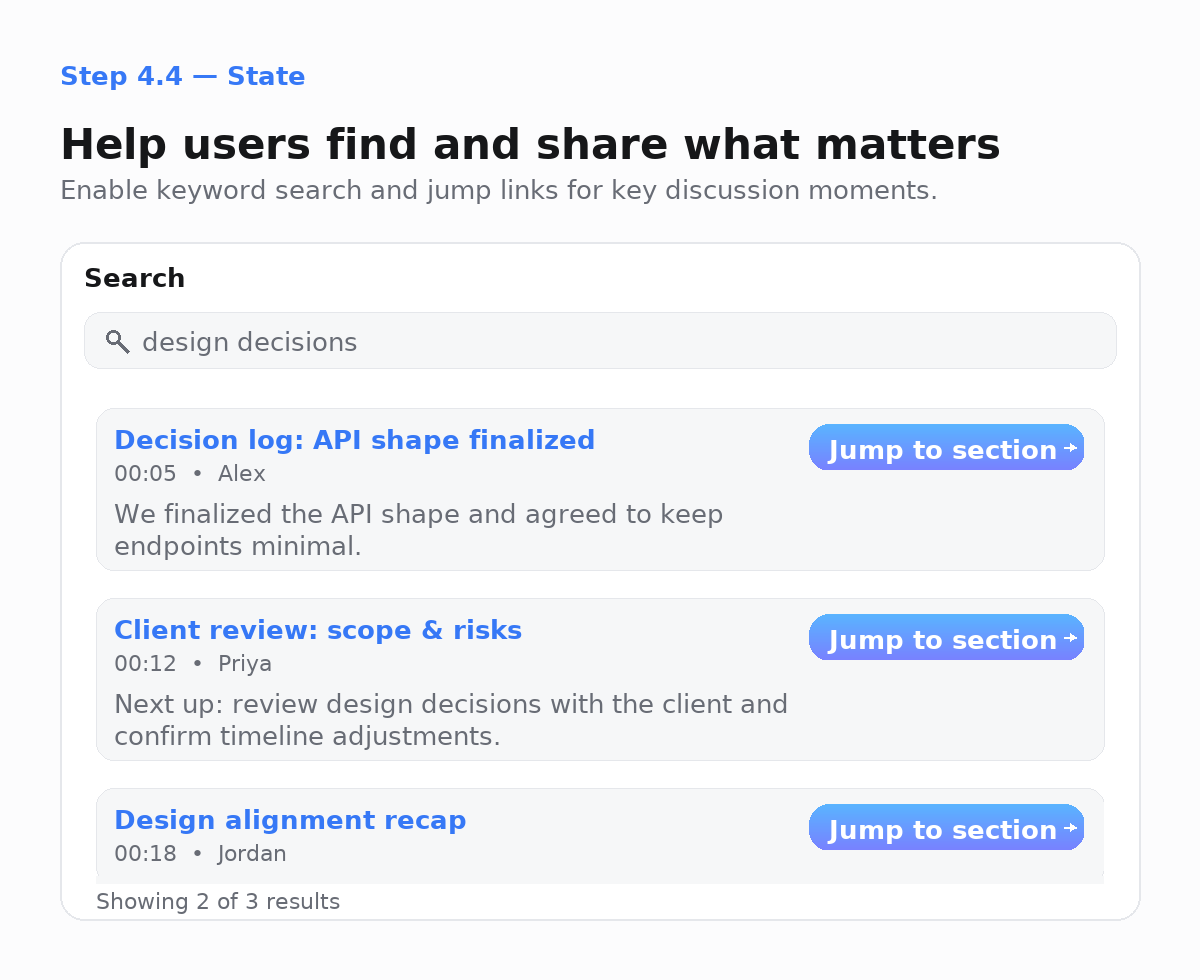
The snippets below show a basic in-memory search and how to deliver highlights via Slack or your own UI. You can transition from in-memory to your own database.
//@title app/step4.py - search + jump links (excerpt)
from typing import List, Dict, Any, Tuple
def search_paragraphs(paragraphs: List[Dict[str, Any]], query: str, limit: int = 5
) -> List[Tuple[Dict[str, Any], int]]:
q = query.lower().strip()
scored: List[Tuple[Dict[str, Any], int]] = []
for p in paragraphs:
score = p["text"].lower().count(q)
if score: scored.append((p, score))
scored.sort(key=lambda t: (-t[1], t[0]["start_ms"]))
return scored[:limit]
def jump_link(base_play_url: str, start_ms: int) -> str:
"""
Create a link your player can understand (e.g., /play?bot_id=...&t=342).
Keep it aligned with how your frontend seeks into the MP4.
"""
sec = max(0, start_ms // 1000)
sep = "&" if "?" in base_play_url else "?"
return f"{base_play_url}{sep}t={sec}"
And here’s a minimal Slack helper that uses jump_link() to post highlights to your chosen channel.
//@title app/step4.py — Slack webhook (excerpt)
import httpx
from typing import List, Dict, Any
async def post_to_slack(webhook_url: str, title: str, highlights: List[Dict[str, Any]], base_play_url: str):
blocks = [{"type": "section", "text": {"type": "mrkdwn", "text": f"*{title}*"}}]
for h in highlights[:5]:
t = jump_link(base_play_url, h.get("start_ms", 0))
blocks.append({"type": "section", "text": {"type": "mrkdwn", "text": f"• {h.get('title','')} — <{t}|jump>"}})
async with httpx.AsyncClient(timeout=15) as http:
await http.post(webhook_url, json={"blocks": blocks})
Check out the appendix for one FastAPI route that puts all of these steps together.
4.5 Enrich the meeting with participant, audio, and video context (optional)
Once you’ve built a transcript-based view, you can layer in other meeting signals to give users richer context.
This step is optional, but it’s what turns your transcript into a more complete view of the meeting, combining what was said with what was happening in the room.

See what other participants were doing during the meeting
Participant events such as join/leave, mute/unmute, camera on/off, screenshare on/off, and chat messages, can be attached to the transcript paragraphs that occur during each event’s timestamp window.
//@title app/step4.py - events → paragraphs (excerpt)
import httpx
from typing import Any, Dict, List
async def load_events_json(url: str) -> Dict[str, Any]:
async with httpx.AsyncClient(timeout=60) as http:
r = await http.get(url)
r.raise_for_status()
return r.json()
def enrich_paragraphs_with_events(paragraphs: List[Dict[str, Any]], events: List[Dict[str, Any]]):
"""Attach participant events to paragraphs that overlap in time."""
for p in paragraphs:
start, end = p.get("start_ms", 0), p.get("end_ms", 0)
p["events"] = [e for e in events if start <= e.get("ts_ms", 0) <= end]
This lets you show small badges like [chat] or [camera on] next to each paragraph or visualize a timeline of meeting activity.
Understand who spoke the most (and for how long)
You can use Recall.ai’s speech_on and speech_off events to calculate speaker talk time.
You can also approximate speaker talk time by summing each speaker’s paragraph durations.
//@title app/step4.py - speaker stats (excerpt)
from typing import List, Dict, Any, Optional
from collections import defaultdict
def compute_speaker_stats(paragraphs: List[Dict[str, Any]], events: Optional[List[Dict[str, Any]]] = None) -> Dict[str, Dict[str, int]]:
"""
Returns per-speaker totals:
{ speaker: { "talk_time_ms": int, "turns": int }, ... }
Prefers speech_on/off events; falls back to paragraph durations.
"""
segs = defaultdict(list)
on: Dict[str, int] = {}
# Prefer accurate talk-windows from events if present
for e in (events or []):
who = (e.get("participant") or {}).get("name") or "Speaker"
if e.get("type") == "speech_on":
on[who] = e.get("ts_ms", 0)
elif e.get("type") == "speech_off" and who in on:
segs[who].append((on.pop(who), e.get("ts_ms", 0)))
# Fallback to paragraph durations
if not segs:
for p in paragraphs:
who = p.get("speaker") or "Speaker"
segs[who].append((p.get("start_ms", 0), p.get("end_ms", 0)))
return {
spk: {
"talk_time_ms": sum(b - a for a, b in segs[spk]),
"turns": len(segs[spk]),
}
for spk in segs
}
Show what was happening on screen
To help users see what was happening, you can grab thumbnails from the mixed MP4 at paragraph starts or at screenshare events.
This example uses FFmpeg, but any thumbnail-generation library or service works.
//@title app/step4.py - video thumbnails (excerpt)
import subprocess
from pathlib import Path
def thumbnail_at(video_path: str, ms: int, out_dir: str) -> str:
"""Extract a single frame from an MP4 at the given millisecond timestamp."""
out = Path(out_dir) / f"thumb_{ms}.jpg"
ss = f"{ms/1000:.3f}"
subprocess.run(
["ffmpeg", "-y", "-ss", ss, "-i", video_path,
"-frames:v", "1", "-vf", "scale=480:-1", str(out)],
check=True, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL
)
return str(out)
Each thumbnail can be paired with a jump_link() so users can click straight to that timestamp in playback.
Why meeting context matters
Transcripts show what was said, which is enough for summaries. To create action items and gather basic analytics, speaker diarization separates the content by speaker. Participant events fill in the rest: who joined or left, muted or unmuted, turned cameras on or off, or shared screens. Thumbnails add quick visual cues so users can see what was happening at key moments.
In your UI, these enrichments can enable a timeline of speaking activity and screenshares, such as a speaker sidebar with talk-time stats, and a highlights grid with thumbnails and jump links. Together, they turn a transcript into a meeting record that captures both the conversation and the flow of the meeting. These are just a few examples. How you use and build on conversation data is entirely up to you.
Optional: Stream video/audio into the meeting
I’ve talked about the data that my meeting bot can get out of a meeting and what it can do with that data, but because my bot is a meeting participant, it can do more than ingest meeting data; it can also output content into the meeting. I’ll use Recall.ai’s Output Media API to display video, audio, images, and more in the meeting.
Using Output Media allows my bot to programmatically show a “Recording in progress” slate, give the bot a custom avatar and voice to interact in the meeting, play hold music, or write chat messages.

I can also use Recall.ai to embed AI agents inside meetings. With the conversation data Recall.ai streams from the meeting to my service, agents can reason about what’s happening and then generate output to push back into the meeting. Because this tutorial is not about building AI agents, I won’t dive deep into this, but you can check out our docs if you want to learn more.
Where Output Media lives in the Meeting Bot API
To enable a bot to send data back into the meeting and to have it record its own audio, configure output settings inside recording_config when creating the bot via the Create Bot endpoint. In the code snippet below, I set output_media, automatic_video_output, automatic_audio_output.
//@title app/pythonHowToBuildABot — /start (output media excerpt)
recording_config.update({
"automatic_video_output": {
"in_call_recording": {
# Pick exactly one of these (example placeholders):
# "image_url": "https://yourcdn.example/slates/recording.png"
# "webpage": { "url": "https://yourapp.example/live-preview" }
},
"in_call_not_recording": {
# Optional fallback image/webpage
# "image_url": "https://yourcdn.example/slates/standby.png"
}
},
"automatic_audio_output": {
"in_call_recording": {
# Optional audio:
# "audio_url": "https://yourcdn.example/audio/hold.ogg"
}
},
"output_media": {
# Choose exactly one per docs; example:
# "webpage": { "url": "https://yourapp.example/demo" }
# or "camera": {...} or "screenshare": {...}
}
})
If I wanted to change what the bot was outputting during a meeting, I could use the Stream Media endpoints to swap sources on the fly (for example, swap from a “Recording in progress” slate to an AI avatar).
Conclusion
At this point, you’ve seen the full arc: Create a bot -> subscribe to events -> retrieve recordings -> process and deliver useful insights -> (optionally) stream video/audio into the meeting.
The meeting bot form factor gives you a direct presence in the meeting. Your bot joins like any participant. That visibility means it can both capture data and contribute to the meeting, making it ideal for real-time use cases, interactive agents, or in-meeting displays.
If you don’t like the idea of a bot in the meeting, the Desktop Recording SDK takes a different approach. It lets your app record directly from the user’s device without a bot joining the meeting. This makes it discreet, perfect for on-device capture, or environments where bots can’t join.
For both the Meeting Bot API and the Desktop Recording SDK, you can go from idea to production in days, instead of months.
If you’re ready to build your first bot, sign up for an account, check out the quickstart guide, and start turning conversations into insights your users will actually use. And if you ever need a hand, we’re just a message away because, like our bots, we never really sleep.
Appendix
Exhaustive Create Bot cURL example
//@title Full Create Bot example (appendix): maximal options in one request
# - Uses recallai_streaming (real-time)
# - Includes platform + meeting_password
# - Sets display name + avatar
# - Captures transcript, mixed A/V, and per-participant audio
# - Subscribes to webhook + websocket for realtime events
# - Chooses layout + example capacity variant
# - Configures output media (image/webpage) independent of recording
curl -X POST "https://$RECALL_REGION.recall.ai/api/v1/bot" \
-H "authorization: Token $RECALL_API_KEY" \
-H "content-type: application/json" \
-d @- <<'JSON'
{
"meeting_url": "PASTE_YOUR_MEETING_LINK",
"platform": "zoom",
"meeting_password": "OPTIONAL_MEETING_PASSWORD",
"bot_name": "YOUR_BOT_NAME",
"bot_avatar_url": "https://yourcdn.example/assets/bot-avatar.png",
"external_id": "ext-123",
"recording_config": {
"transcript": {
"provider": {
"recallai_streaming": {
"language_code": "en",
"filter_profanity": false,
"mode": "prioritize_low_latency"
}
}
},
"participant_events": {},
"meeting_metadata": {},
"video_mixed_mp4": {},
"audio_mixed_mp3": {},
"audio_mixed_raw": {},
"audio_separate_mp3": {},
"video_separate_h264": {},
"video_mixed_layout": "gallery_view_v2",
"include_bot_in_recording": { "audio": true, "video": false },
"start_recording_on": "participant_join",
"realtime_endpoints": [
{
"type": "webhook",
"url": "NGROK_BASE/wh",
"events": [
"transcript.data",
"participant_events.join","participant_events.leave","participant_events.update",
"participant_events.speech_on","participant_events.speech_off",
"participant_events.webcam_on","participant_events.webcam_off",
"participant_events.screenshare_on","participant_events.screenshare_off",
"participant_events.chat_message",
"bot.status_change"
]
},
{
"type": "websocket",
"url": "NGROK_BASE/ws/rt?token=WS_TOKEN",
"events": ["audio_mixed_raw.data","video_separate_h264.data"]
}
],
"automatic_video_output": {
"in_call_recording": {
"image_url": "https://yourcdn.example/slates/recording.png"
},
"in_call_not_recording": {
"image_url": "https://yourcdn.example/slates/standby.png"
}
},
"automatic_audio_output": {
"in_call_recording": {
"audio_url": "https://yourcdn.example/audio/hold.ogg"
}
},
"output_media": {
"webpage": { "url": "https://yourapp.example/demo" }
}
}
}
JSON
How to use the Recall.ai Calendar Integration
Recall.ai automatically detects and syncs meeting links from your connected calendar events, regardless of the provider (Zoom, Google Meet, Microsoft Teams, etc.).
To enable it:
- Go to your Recall.ai dashboard and open the
Setup & Integrationstab. - When your users connect their calendars, bots will be scheduled for any upcoming events that include a meeting link.
This integration ensures your Recall.ai meeting bot always joins the correct meeting without you having to write bot scheduling code yourself.
Recommended event matrix & reliability checklist
Event Matrix
| Goal | Event(s) | When to Act |
|---|---|---|
| Live captions / coaching | transcript.data (and optional transcript.partial_data) |
Append to UI; stream to LLM |
| Detect meeting lifecycle | bot.status_change |
Show “joining,” “recording,” “processing,” “done” |
| Fetch post-meeting artifacts | bot.status_change → bot.done |
Retrieve transcript and media |
| Ops monitoring | bot.status_change (failures) |
Alert and auto-retry |
Webhook reliability, retries, and idempotency
When running in production, you’ll need to account for how Recall.ai delivers webhook events. Unlike your local, happy-path demos, production workloads introduce network latency, occasional downtime, and event retries. This section covers how to make your webhook handling reliable and idempotent.
Why retries happen
Recall.ai retries webhook deliveries if your server doesn’t acknowledge quickly enough with a 2xx status code. This ensures that events aren’t silently dropped due to transient network failures or slow handlers. As a result, you will see duplicate events in production. Your code needs to handle them safely.
The safe handling pattern
-
Ack fast
-
Return a
2xxresponse as soon as you receive the event. -
Don’t do heavy work in the webhook handler itself. Instead, enqueue the event (e.g., send it to a job queue like Redis, RabbitMQ, SQS, or a simple async task runner) and let the worker handle the rest.
-
Implement retries for downstream network operations like media downloads. Use exponential backoff and jitter.
-
-
Deduplicate
-
Each event payload includes enough information to uniquely identify it. Use
external_idto correlate the meeting, bot, and storage objects. Maintain a short-TTL event ledger to prevent reprocessing duplicates. -
A common pattern is to deduplicate on a composite key:
(event_type, bot_id, updated_at) -
For example, if you receive multiple
transcript.dataevents with the same timestamp window, you can safely ignore duplicates. -
Some events may include an
event_idfield in the payload. If theevent_idis present, that’s the easiest dedupe key.
-
-
Idempotent writes
-
Database operations should be safe to run more than once.
-
For transcripts, a reliable approach is to UPSERT based on
(timestamp, text hash). This ensures that even if you process the same segment twice, you won’t create duplicates. -
For participant events, UPSERT on
(participant_id, updated_at). -
For all event types, keep a copy of the raw JSON payload with parsed models for auditing and troubleshooting.
-
Example: Transcript dedupe
Say you receive this transcript event:
{
"event": "transcript.data",
"data": {
"bot_id": "abc123",
"updated_at": "2025-10-02T20:41:00Z",
"data": {
"start_ms": 156000,
"end_ms": 158000,
"text": "Let's wrap up the agenda."
}
}
}
You can use (event_type, bot_id, updated_at) as your dedupe key, or (start_ms, end_ms, md5(text)) for transcript-specific UPSERTs. Either way, replays won’t create duplicate rows.
Special note: raw media streams
If you subscribe to audio or video via WebSocket, expect high-frequency data delivery (often many messages per second). For example, audio_mixed_raw.data at 16 kHz, mono, signed 16-bit PCM means each audio sample is two bytes, so 32 bytes ≈ 1 ms of audio. That’s why in examples you’ll often see: duration_ms = len(decoded_bytes) // 32.
This calculation is handy when you want to timestamp or segment raw audio buffers consistently. When downloading or processing raw media in production, add retry logic with exponential backoff and jitter to handle transient errors gracefully.
Multiple recordings from a single meeting
A single bot can create multiple recordings when you use the Start Recording/Stop Recording endpoints to control capture during a meeting. Each time you stop and then start recording, Recall.ai creates a new entry in the bot’s recordings array, each with its own transcript and media files.
If you want one continuous recording instead, use the Pause Recording/Resume Recording. Pausing halts both recording and real-time transcription but resumes within the same recording file, creating silent or black-screen gaps rather than new segments.
When you call Retrieve Bot, iterate through the recordings array to access each segment’s artifacts via media_shortcuts.
How to parse media shortcuts from JSON response
//@title app/mediahelpers.py — /start (output media excerpt)
from typing import Any, Dict, List, Optional
def extract_media_shortcuts(bot_json: Dict[str, Any]) -> List[Dict[str, Optional[str]]]:
"""
Returns one dict per recording with fresh, short-lived URLs.
If a given artifact wasn't requested or isn't ready, its URL will be None.
Typical usage:
r = await http.get(f"{API}/bot/{bot_id}", headers=H)
shortcuts = extract_media_shortcuts(r.json())
for s in shortcuts:
print("Transcript:", s["transcript_url"])
print("Mixed video:", s["video_mixed_url"])
print("Mixed audio:", s["audio_mixed_url"])
"""
out: List[Dict[str, Optional[str]]] = []
for rec in bot_json.get("recordings") or []:
shortcuts = rec.get("media_shortcuts") or {}
def url(key: str) -> Optional[str]:
node = shortcuts.get(key) or {}
data = node.get("data") or {}
return data.get("download_url")
out.append({
"recording_id": rec.get("id"),
"transcript_url": url("transcript"),
"video_mixed_url": url("video_mixed"),
"audio_mixed_url": url("audio_mixed"),
})
return out
Fetching Specific Artifacts
For the less-common artifacts, use the recording endpoints. Explicit asset retrieval is required for any of the assets not returned by the Retrieve Bot endpoint. To fetch assets like speaker-separated audio and video, you’ll need to first obtain the specific artifact id (from the Retrieve Bot endpoint) and then hit one of the asset endpoints that Recall.ai exposes, like this one for separate audio:
//@title app/mediaHelpers.py
import os, httpx
from typing import Optional, Tuple
RECALL_REGION = os.getenv("RECALL_REGION", "us-east-1")
RECALL_API_KEY = os.getenv("RECALL_API_KEY", "")
API = f"https://{RECALL_REGION}.recall.ai/api/v1"
H = {"Authorization": f"Token {RECALL_API_KEY}", "Content-Type": "application/json"}
async def extract_audio_separate_id(bot_json: dict) -> Optional[str]:
"""
Return the audio-separate artifact id from the Retrieve Bot JSON, if present.
Checks several likely keys depending on your recording_config.
"""
for rec in bot_json.get("recordings") or []:
for key in ("audio_separate", "audio_separate_mp3", "audio_separate_raw"):
obj = rec.get(key)
if obj and obj.get("id"):
return obj["id"]
return None
async def get_audio_separate_download_url(audio_separate_id: str) -> Tuple[Optional[str], Optional[str]]:
"""
GET /audio_separate/{id}/ and return (download_url, format).
- format: 'raw' or 'ogg' (depends on how the audio was encoded)
- download_url: pre-signed link to all per-participant audio parts for that recording
"""
async with httpx.AsyncClient(timeout=30) as client:
r = await client.get(f"{API}/audio_separate/{audio_separate_id}/", headers=H)
r.raise_for_status()
data = r.json()
d = data.get("data") or {}
return d.get("download_url"), d.get("format")
Practical tips for fetching and storing meeting data
- Don’t cache the URLs. Cache IDs (bot.id, recording.id). If a link 403s later, just call the Retrieve Bot endpoint again and you’ll get fresh
download_urls. - Depending on how users interact with the bot in a meeting, a single meeting can produce multiple recordings. Make sure to iterate through all recordings to get all the data for a meeting as mentioned in the section on multiple recordings for a meeting.
- You can return the URLs directly to your web client for playback/download; they’re already authorized via the signature, so you don’t forward your API key.
Putting all of Step 4 together
Here’s a single FastAPI route that: loads the transcript from your media_shortcuts, flattens the transcript, builds paragraphs, summarizes + extracts actions, and returns everything your UI needs.
//@title app/analyze.py — /analyze
from __future__ import annotations
import json
from typing import Dict, Any, List
import httpx
from fastapi import APIRouter, HTTPException
from app.step4 import load_transcript_json, to_segments, to_paragraphs, build_summary_and_actions, jump_link
router = APIRouter()
def my_generate(prompt: str) -> str:
# Plug in your LLM call; must return JSON string
return json.dumps({"summary": "", "highlights": [], "action_items": []})
@router.post("/analyze")
async def analyze(payload: Dict[str, Any]):
"""
Body:
{
"transcript_url": "https://<short-lived-url-from-media_shortcuts>",
"base_play_url": "https://yourapp.example/play?bot_id=...", // optional (for jump links)
"slack_webhook_url": null | "https://hooks.slack.com/services/..." // optional
}
"""
if not isinstance(payload, dict):
raise HTTPException(status_code=400, detail="Body must be a JSON object")
transcript_url = payload.get("transcript_url")
if not transcript_url or not isinstance(transcript_url, str):
raise HTTPException(status_code=400, detail="Missing required field: transcript_url")
# Load + flatten
try:
tj = await load_transcript_json(transcript_url)
except httpx.HTTPError as e:
raise HTTPException(status_code=502, detail=f"Failed to load transcript: {e}") from e
segs = to_segments(tj)
paras = to_paragraphs(segs)
# Summarize
result = build_summary_and_actions(paras, generate=my_generate)
summary: str = result.get("summary") or ""
highlights: List[Dict[str, Any]] = result.get("highlights") or []
action_items: List[Dict[str, Any]] = result.get("action_items") or []
# Optional Slack digest
slack = payload.get("slack_webhook_url")
base = payload.get("base_play_url") or ""
if slack:
blocks = [{"type": "section", "text": {"type": "mrkdwn", "text": "*Meeting summary*"}}]
for h in highlights[:5]:
title = (h.get("title") or "").strip()
start_ms = int(h.get("start_ms") or 0)
if base:
link = jump_link(base, start_ms)
line = f"• {title} — <{link}|jump>"
else:
mm = max(0, start_ms // 1000) // 60
ss = max(0, start_ms // 1000) % 60
line = f"• {title} — {mm:02d}:{ss:02d}"
blocks.append({"type": "section", "text": {"type": "mrkdwn", "text": line}})
try:
async with httpx.AsyncClient(timeout=15) as http:
await http.post(slack, json={"blocks": blocks})
except Exception:
pass # best-effort
return {
"paragraphs": paras[:200], # trim if needed
"summary": summary,
"highlights": highlights,
"action_items": action_items,
}
Helpers for Step 4
//@title app/step4.py — helpers (load, flatten, paragraphs, summarize, search)
# PII note: transcripts may contain PII. Redact before logging externally.
import httpx, json, subprocess
from pathlib import Path
from typing import Any, Dict, List, Callable, Tuple, Optional
from collections import defaultdict
# Load
async def load_transcript_json(url: str) -> Any:
async with httpx.AsyncClient(timeout=60) as http:
r = await http.get(url)
r.raise_for_status()
return r.json()
# Flatten into segments
def to_segments(transcript_json: Any) -> List[Dict[str, Any]]:
"""
Convert a normalized Recall.ai transcript into a flat list of text segments.
Input shape (guaranteed by Recall.ai):
[
{
"participant": { "name": "Alice", ... },
"words": [
{ "text": "hello", "start_timestamp": {"relative": 0.0}, "end_timestamp": {"relative": 0.4} },
{ "text": "everyone", "start_timestamp": {"relative": 0.4}, "end_timestamp": {"relative": 1.0} }
]
},
...
]
Output shape (used by downstream helpers):
[
{ "speaker": "Alice", "start_ms": 0, "end_ms": 1000, "text": "hello everyone" },
...
]
"""
# If the payload isn't the expected list (e.g., empty or malformed), return nothing.
if not isinstance(transcript_json, list):
return []
out: List[Dict[str, Any]] = []
# Each entry represents one speaker turn (a participant + their spoken words)
for entry in transcript_json:
words = (entry or {}).get("words") or []
if not words or not isinstance(words, list):
continue # skip empty or invalid word lists
# Extract relative timestamps (in seconds) and convert to milliseconds.
# We use the first word's start and last word's end to bound the segment.
try:
start_rel = float(words[0]["start_timestamp"]["relative"])
end_rel = float(words[-1]["end_timestamp"]["relative"])
except (KeyError, TypeError, ValueError):
# If timestamps are missing or malformed, skip this segment.
continue
# Join all word texts into a single line of readable text.
text = " ".join((str(w.get("text", "")).strip() for w in words)).strip()
if not text:
continue
# Use the participant's display name if available.
speaker = ((entry.get("participant") or {}).get("name")) or None
# Append the flattened segment.
out.append({
"speaker": speaker,
"start_ms": int(start_rel * 1000),
"end_ms": int(end_rel * 1000),
"text": text
})
return out
# Paragraphs
def to_paragraphs(segments: List[Dict[str, Any]], gap_ms: int = 1200) -> List[Dict[str, Any]]:
out: List[Dict[str, Any]] = []
cur: Dict[str, Any] | None = None
for s in sorted(segments, key=lambda x: x["start_ms"]):
new_block = (cur is None or s.get("speaker") != cur.get("speaker") or s["start_ms"] - cur["end_ms"] > gap_ms)
if new_block:
if cur: out.append(cur)
cur = dict(s)
else:
cur["end_ms"] = max(cur["end_ms"], s["end_ms"])
cur["text"] = (cur["text"] + " " + s["text"]).strip()
if cur: out.append(cur)
return out
# Summarize
def build_summary_and_actions(
paragraphs: List[Dict[str, Any]],
generate: Callable[[str], str],
max_chars: int = 15000
) -> Dict[str, Any]:
def fmt_time(ms: int) -> str:
s = max(0, ms // 1000); return f"{s//60:02d}:{s%60:02d}"
lines = []
for p in paragraphs:
speaker = p.get("speaker") or "Speaker"
ts = fmt_time(p.get("start_ms", 0))
lines.append(f"[{ts}] {speaker}: {p['text']}")
text = "\n".join(lines)[:max_chars]
prompt = f"""
You are turning a meeting transcript into structured, linkable notes.
Return STRICT JSON with keys: summary, highlights[], action_items[].
- highlights[]: title, start_ms, end_ms, quote
- action_items[]: title, owner (email or null), due_date (YYYY-MM-DD or null), confidence (0..1), evidence_ms
Only use information present in the transcript below.
Transcript:
{text}
""".strip()
raw = generate(prompt)
try:
data = json.loads(raw)
data.setdefault("summary",""); data.setdefault("highlights",[]); data.setdefault("action_items",[])
return data
except Exception:
return {"summary": "", "highlights": [], "action_items": []}
# Search
def search_paragraphs(paragraphs: List[Dict[str, Any]], query: str, limit: int = 5
) -> List[Tuple[Dict[str, Any], int]]:
q = query.lower().strip()
scored: List[Tuple[Dict[str, Any], int]] = []
for p in paragraphs:
score = p["text"].lower().count(q)
if score: scored.append((p, score))
scored.sort(key=lambda t: (-t[1], t[0]["start_ms"]))
return scored[:limit]
def jump_link(base_play_url: str, start_ms: int) -> str:
sec = max(0, start_ms // 1000)
sep = "&" if "?" in base_play_url else "?"
return f"{base_play_url}{sep}t={sec}"
