







In this post, I built a bot that joins a Microsoft Teams call and streams the transcript in real time.
As a developer experience engineer at Recall.ai, I’ve heard many stories of developers struggling to build their own Microsoft Teams bots. In an effort to better understand the challenges that developers face when tasked with getting transcripts from Microsoft Teams meetings, I set out to build my own Microsoft Teams bot from scratch.
To guide the project, I kept the requirements simple. The bot needed to:
-
Retrieve transcripts in real-time.
-
Operate without requiring a heavy lift from participants.
The code is open-source and can be found in the Microsoft Teams Meeting Bot GitHub repository. Watch the demo below to see the bot emitting transcripts in real-time 👇
We also have separate posts on how to get meeting transcripts for Zoom and Google Meets meetings:
If you’re looking for bot-less ways to get the transcript from meetings, check out the Recall.ai Desktop Recording SDK.
Choosing an implementation: Graph API vs. Playwright
When I first sat down to figure out how to build a Microsoft Teams recording bot, two paths opened up in front of me: use the official Microsoft Graph API, or use browser-automations. I’ll dive into both paths and talk about what I considered when evaluating each solution. You can also see a quick comparison in the Appendix under Summary of implementations evaluated.
Option 1 - Retrieving meeting captions from the Microsoft Graph API
Getting transcripts from Microsoft Teams can be approached in a few ways. One option highlighted in Microsoft’s documentation is to use the Microsoft Graph API, which includes the callTranscript() method to fetch transcripts once a meeting has ended.
The core problem with using the Microsoft Graph API was that the Microsoft Teams app you built had to be installed on the tenant that hosted the call. That meant if your user met with another company, and the other company hosted the call, their IT department had to have installed and authorized your Microsoft Teams app in their organization’s Microsoft Teams tenant before it could be used. It wasn’t enough for the app to be installed on your user’s own tenant.
In practice, this made it almost impossible to capture meetings hosted by other organizations, which was exactly the scenario where developers most often needed bots. Additionally I also wouldn’t be able to record the meeting if I wasn’t the host. The option of using the Microsoft Graph API was not sufficient for this project because it would only work if the host had installed the Microsoft Teams app on their tenant.
Option 2 - Scraping meeting captions using browser automations with Playwright (the option I picked)
This was the straightforward option because browser automations allowed me to build a flexible, permissionless bot that had all the same capabilities of any other participant. The only concern was the brittle nature of this implementation as changes to the Microsoft Teams client DOM breaks the bot.
Because my priorities were to make a real-time transcription bot which ran seamlessly without involving participants, the brittleness of this option was a tradeoff I could accept.
The final meeting bot architecture
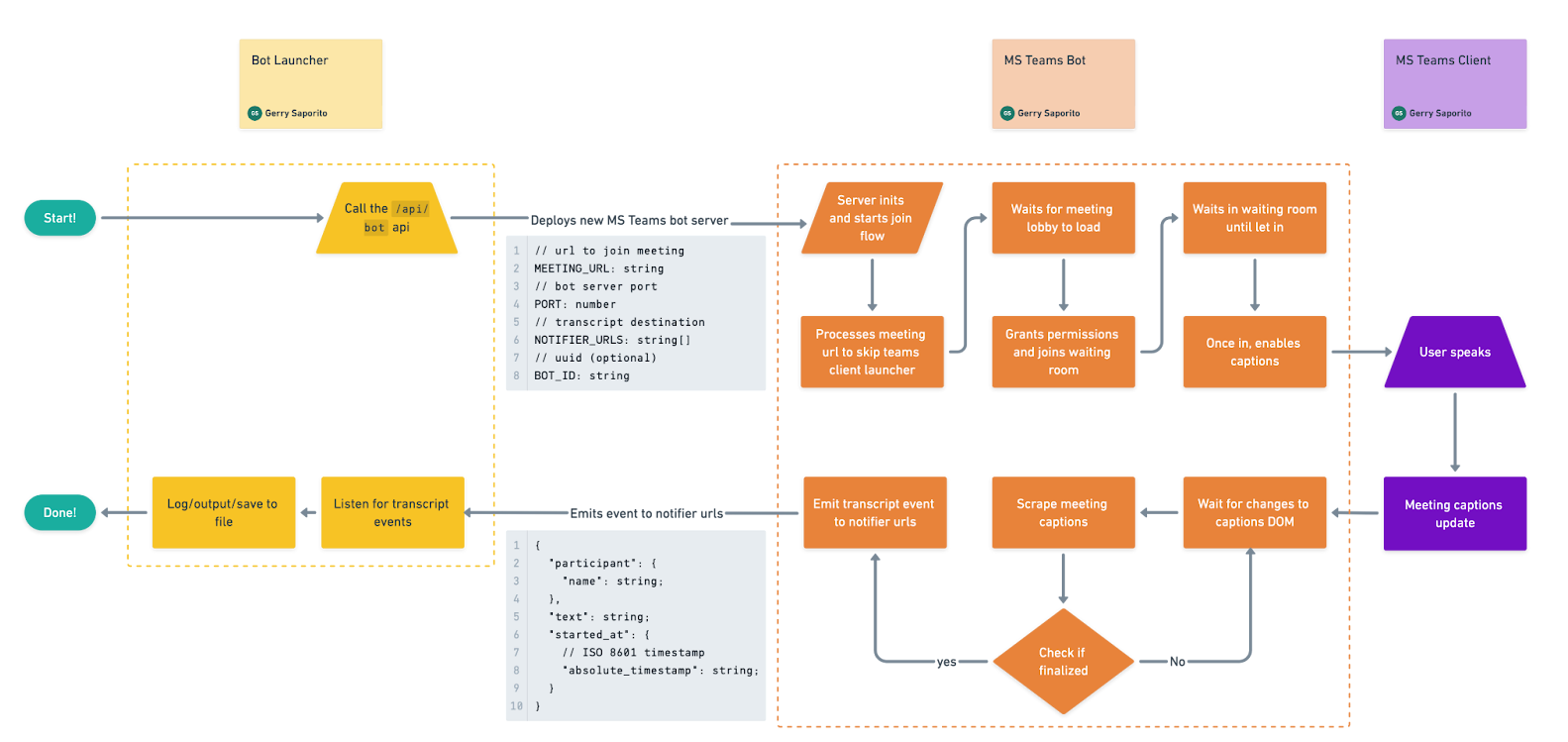
Now that I’d chosen the browser automation implementation, my next task was to map out the architecture. I decided to build two servers with distinct responsibilities:
-
Bot launcher server - a dedicated service whose only job is to programmatically spin up new Microsoft Teams bot instances whenever a call needs to be joined.
-
Microsoft Teams bot server - where the bot instances actually run. Each one uses browser automation to join a meeting and pull captions in real time.
By separating these roles, I kept the bot-launching logic isolated while letting the bots themselves focus solely on the automations required inside the meeting.
Bot launcher server (deploy bots, receive captions)
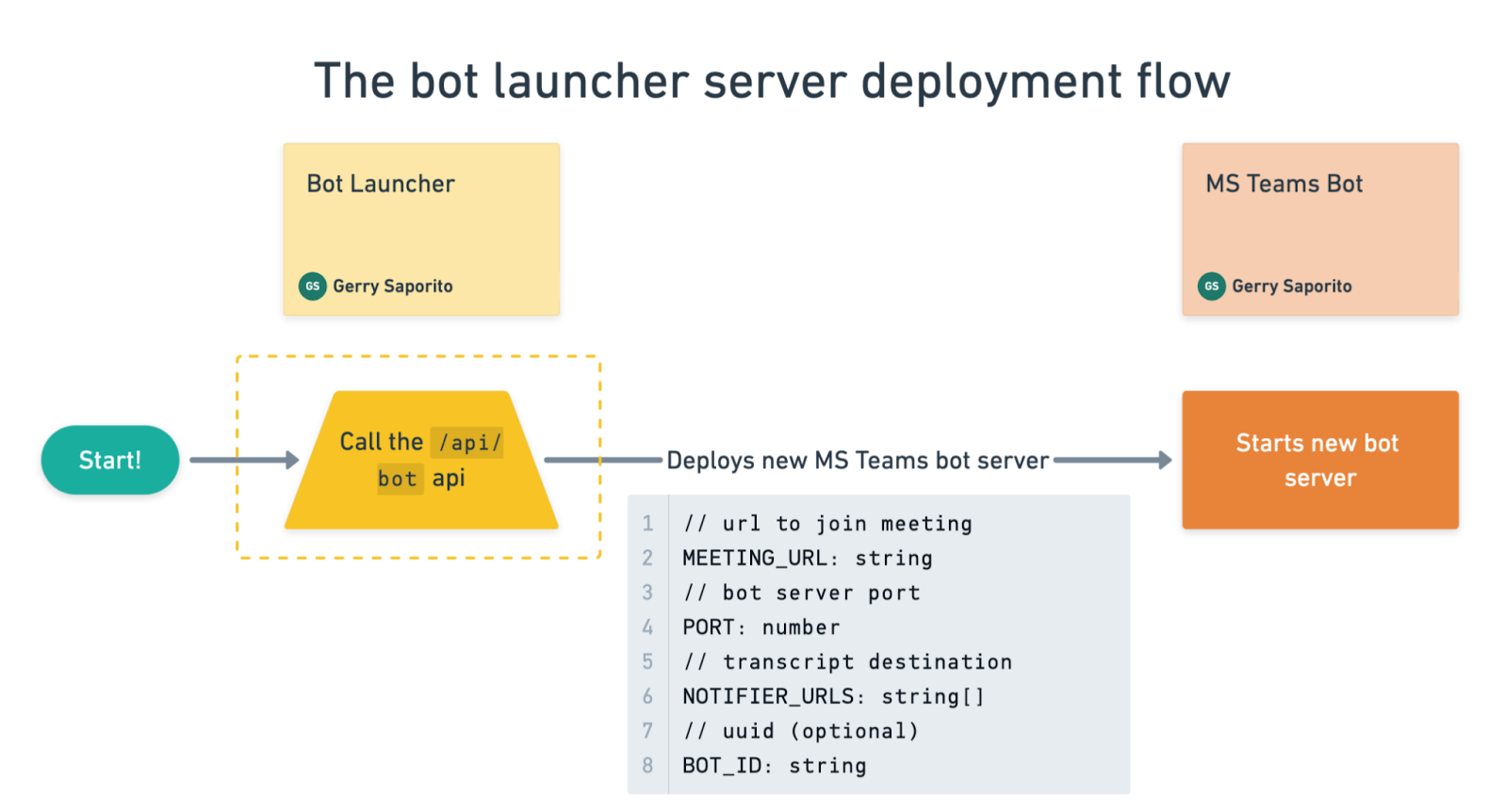
The bot launcher server’s role was to deploy Microsoft Teams Bot instances on demand. It also receives the real-time transcription webhook or websocket events from the bot.
The flow began with a call to the /api/bot endpoint, which deployed a new Microsoft Teams bot. This endpoint accepted the following parameters:
-
Meeting url (required) - the Microsoft Teams meeting to join.
-
Notifier URLs (required) - a list of endpoints to receive transcript utterances in real time.
-
Bot port (optional) - useful when running multiple bots on the same machine, since it lets you control which port a bot binds to.
-
Bot id (optional) - a custom id for logging and debugging.
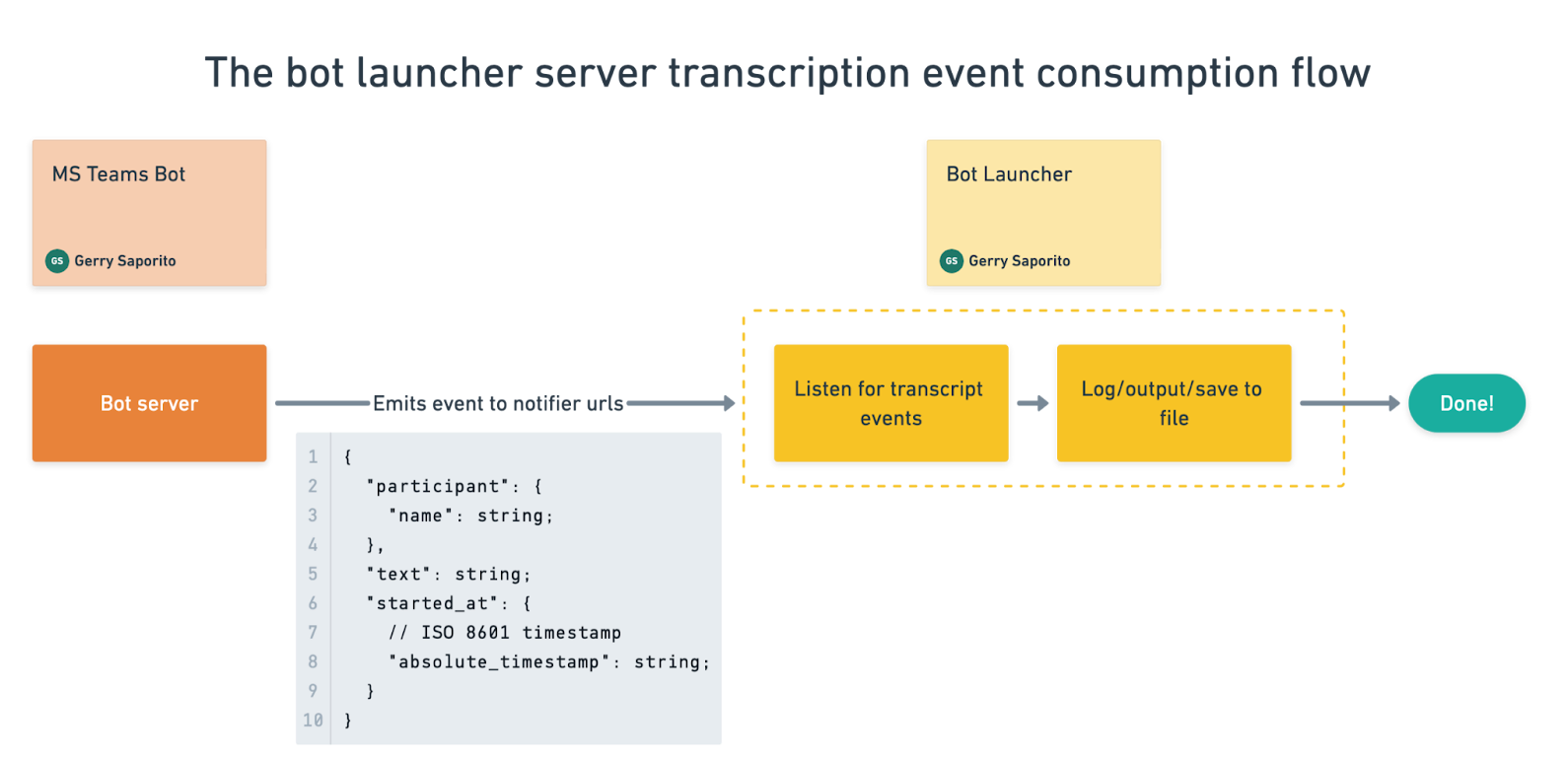
When a participant speaks in the call, the bot launcher server receives real-time transcription events either by subscribing to the webhook endpoint /api/wh/botor listening to the WebSocket on /api/ws/bot.
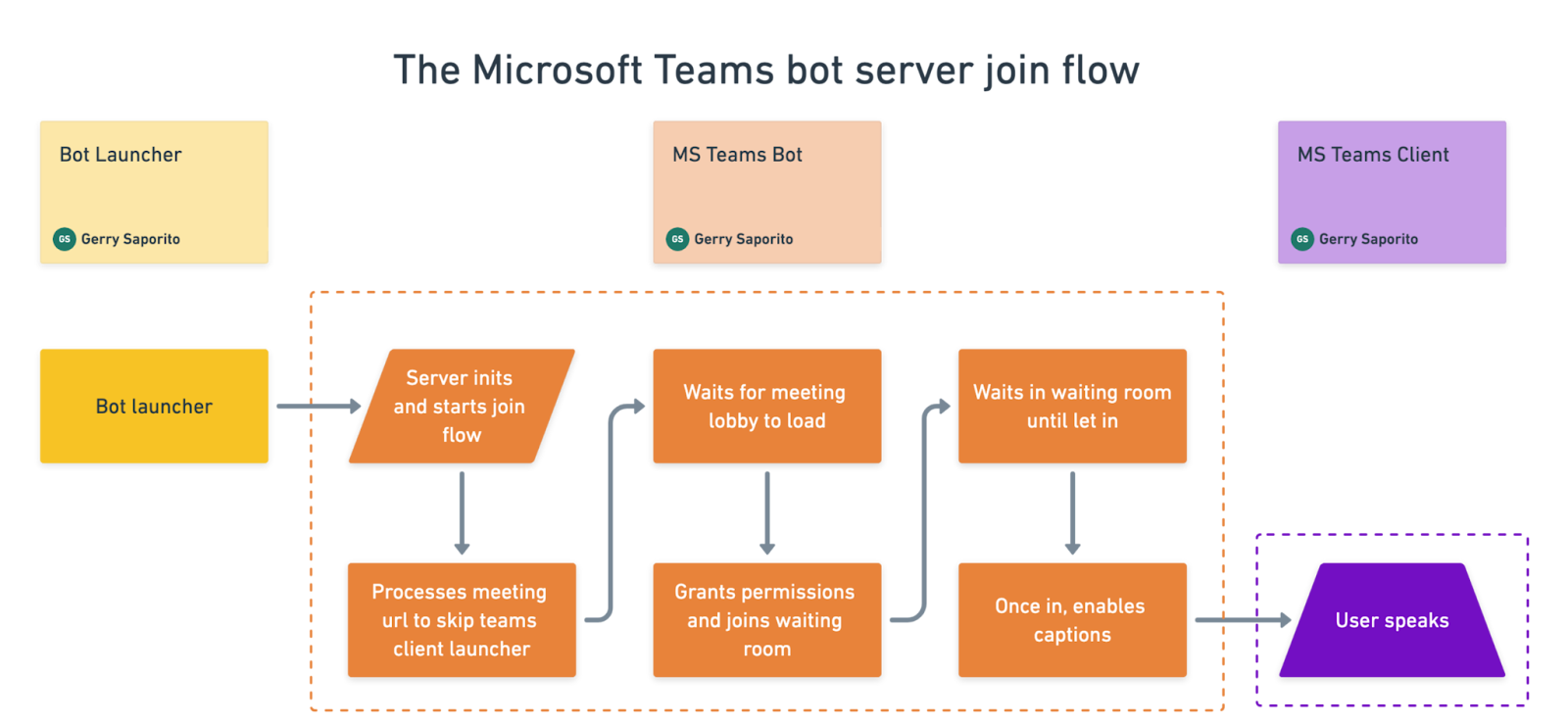
Microsoft Teams bot server (join meetings, scrape and emit captions)
Once started, the bot parses the meeting URL, loads the meeting lobby where it grants permissions and fills out the display name, and enters the waiting room.
Once in the call, the bot enables and watches the captions for changes. Then it detects the finalized transcript utterances and emits them back to the bot launcher server.
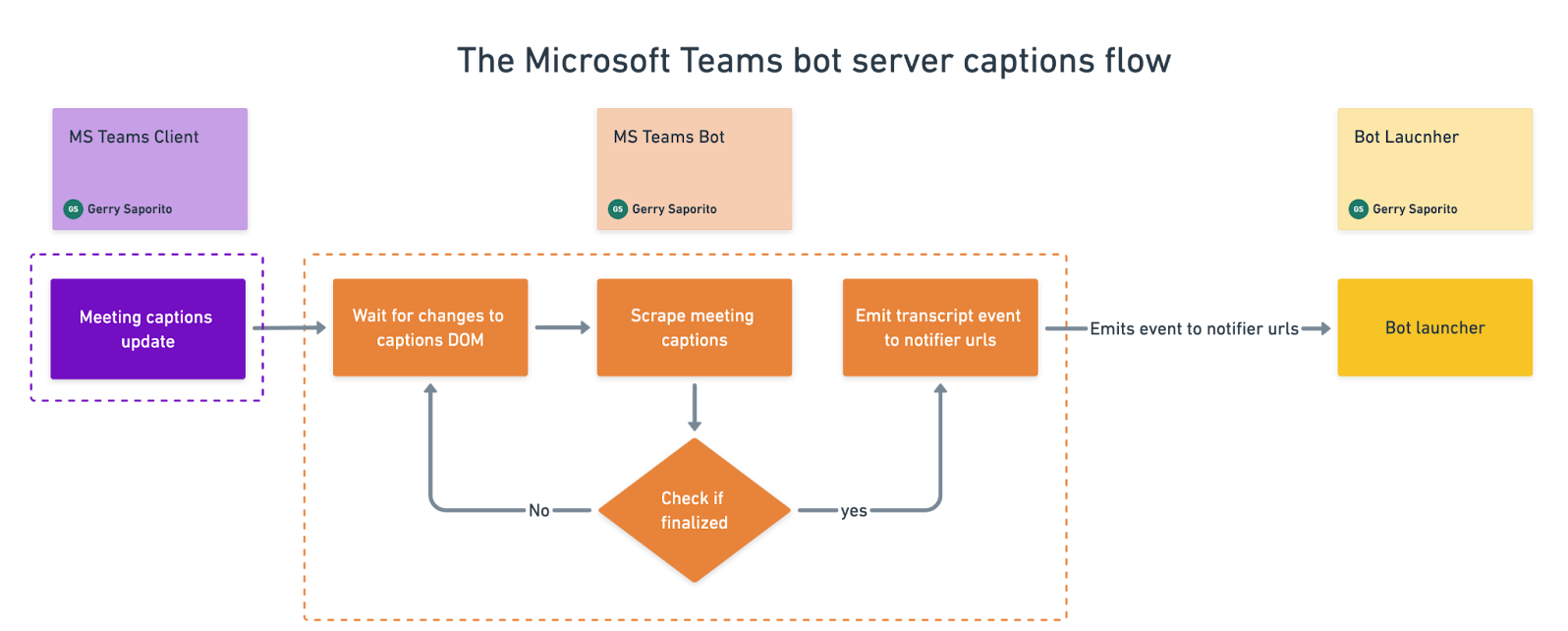
You can see the entire flow in the Appendix under Finalized Implementation Flow.
Building the Microsoft Teams bot server
After I laid out the architecture and implementation, the next task was to start building out the monorepo. I’ll start by walking you through how I set up the bot to join Microsoft Teams calls.
Step 1: Creating the browser
The first step in building the bot was setting up Playwright which would be used for scripting the browser automations. Playwright made it easy to spin up a browser inside a Docker container with just a few lines of code. It also includes built-in arguments to accept browser permissions and mock hardware like audio and video.
//@title apps/teams-bot/src/procedures/orchestrator.ts
this.browser = await chromium.launch({
headless: process.env.NODE_ENV === 'production' ? true : false,
args: [
'--no-sandbox', // Turns off Chrome’s security sandbox so it can run in restricted/containerized environments.
'--disable-setuid-sandbox', // Prevents startup crashes in docker systems without it.
'--disable-dev-shm-usage', // Avoids the “Aw, Snap!” crashes in Docker due to not enough memory
'--use-fake-ui-for-media-stream',// Automatically “clicks allow” on camera/microphone permission prompts
'--use-fake-device-for-media-stream' // Provides a fake/mock webcam/microphone feed
]
});
I then opened a new page in the browser and attempted to load the meeting URL.
Step 2: Processing the Microsoft Teams meeting URL
After opening the Playwright script, the next step was to open the meeting lobby page. However, Microsoft Teams links are app launcher links, not direct links to join the meeting lobby.
Hurdle 1: The unskippable “Launch this in Microsoft Teams” Popup
I realized quickly that the meeting URL didn't allow direct joining, instead opening a dialog box that said “Open in app or browser” which Playwright can’t interact with. The solution was to tweak the query parameters to bypass the dialog and go straight to the browser join flow.
//@title apps/teams-bot/src/procedures/join-procedure.ts
const response = await fetch(meetingUrl, { redirect: 'follow' });
const launchUrl = new URL(response.url);
launchUrl.searchParams.set('msLaunch', 'false');
launchUrl.searchParams.set('type', 'meetup-join');
launchUrl.searchParams.set('directDl', 'true');
launchUrl.searchParams.set('enableMobilePage', 'true');
launchUrl.searchParams.set('suppressPrompt', 'true');
return launchUrl;
This allowed the bot to interact with the DOM because it skipped the popup.
Hurdle 2: Forcing Microsoft Teams to provide a consistent DOM experience
Immediately after I resolved the first hurdle, I encountered another issue: the DOM selectors changed depending on whether the browser was headed or headless. As it turns out, Microsoft Teams serves different DOMs depending on the participant’s browser, making it difficult to reliably find the right selectors.
To work around this, I locked the Microsoft Teams client build by setting a specific user agent so the DOM selectors remained consistent.
//@title apps/teams-bot/src/procedures/orchestrator.ts
const context = await this.browser.newContext({
viewport: { width: 1280, height: 720 },
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
});
Once I set the above user agent, choosing the selectors on headed vs headless browsers became straightforward.
Step 3: Joining the Microsoft Teams meeting
After parsing the direct join link, I loaded the page, entered the bot's display name, and found the "Join meeting" button. Identifying DOM selectors and filling inputs was straightforward. That said, the flow became a lot more interesting when the bot clicked the “Join meeting” button.
Hurdle 3: Handling Microsoft Teams’ many join states
Once the bot clicked the ‘Join meeting’ button, the number of possible states expanded significantly. Microsoft Teams threw the bot into all sorts of states: in waiting room, denied entry, and various error states, each with its own DOM structure and selectors.
I could have detected and supported every state with selectors, but that makes the bot complex and fragile. A simpler approach was to wait for the bot to enter the meeting lobby and fire a timeout if it never entered.
//@title apps/teams-bot/src/procedures/join-procedure.ts
async isInMeetingLobby(page) {
try {
const meetingLobbyText = 'Someone will let you in shortly';
await expect(page.getByText(meetingLobbyText)).toBeVisible({ timeout: waitForSeconds * 1000 });
return true;
} catch (error) {
console.error(error)
return false;
}
}
This approach worked well because my goal was to reliably know when the bot had entered the meeting and to throw/shut down if it didn’t.
Step 4: Enable and scrape real-time captions
By this point, the bot was in the call as a participant and the next step was to start captions by clicking the “Enable captions” button.
The tricky part was scraping captions, since Microsoft Teams buries them deep in the DOM. I had to trace through multiple layers of span and div elements to find a consistent selector that reliably exposed the caption text.
Captions in Microsoft Teams are brittle by design: they rely on deeply nested, unstable DOM elements so even small frontend changes can break this captions flow.
Then I encountered the hardest part: the captions inside the elements were dynamic.
Hurdle 4: Scraping dynamic captions in Microsoft Teams
After fixing the selector, another issue appeared: Microsoft Teams first injected a caption node, then updated it with finalized text. The bot grabbed the partial caption too early, since the text initally appeared incomplete before being updated again moments later.

The only way around this was to watch for changes on the node. I used a MutationObserver on the caption container to track real-time changes and updates to caption content, letting the bot capture the new transcripts as Microsoft Teams injected or updated them.
//@title apps/teams-bot/src/procedures/captions-procedure.ts
await this.page.evaluate(() => {
const targetNode = document.querySelector('div[data-tid="closed-caption-renderer-wrapper"]');
if (!targetNode) return;
const observer = new MutationObserver((mutationsList) => {
for (const mutation of mutationsList) {
if (mutation.type !== 'childList') continue;
mutation.addedNodes.forEach((node) => {
const captionMessage = (node as HTMLElement).querySelector?.('.fui-ChatMessageCompact');
if (!captionMessage) return;
const authorElement = captionMessage.querySelector('span[data-tid="author"]');
const contentElement = captionMessage.querySelector('span[data-tid="closed-caption-text"]');
if (!authorElement || !contentElement) return;
// Watch updates to the caption text in real time
const textObserver = new MutationObserver(() => {
const name = authorElement.textContent?.trim() ?? 'Unknown';
const text = (contentElement as any).innerText?.trim() ?? '';
(window as any).onCaption({ participant: { name }, text, started_at: { absolute_timestamp: new Date().toISOString() } });
});
textObserver.observe(contentElement, { childList: true, subtree: true, characterData: true });
});
}
});
observer.observe(targetNode, { childList: true, subtree: true });
});
This
MutationObserverimplementation wasn’t very efficient as it created a new observer for every new caption element, leading to memory and performance issues over time. A better approach would be to use a single observer on the caption container, filtering and tracking child changes within it.
I was able to pull the captions from the meeting reliably by this point, though this relief was short lived as another issue surfaced once I started streaming the captions.
Hurdle 5: Detecting finalized captions
A new problem popped up once I started streaming captions: I wasn’t filtering for captions that have been finalized. Microsoft Teams updated the same caption element multiple times when a participant was speaking, so I’d end up saving partials for the same caption like:
Gerry: Hey
Gerry: Hey this is a
Gerry: Hey this is a dynamic
Gerry: Hey this is a dynamic Capt
Gerry: Hey this is a dynamic caption
Gerry: Hey this is a dynamic caption.
The fix was to only emit captions that have been finalized. I fumbled around the captions for a while until I realized Microsoft Teams has a quirk: it finalized a caption by adding ending punctuation (e.g. !, ?, .)! With this in mind, I then buffered each caption and waited for the ending punctuation to indicate a caption has finalized.
//@title apps/teams-bot/src/procedures/captions-procedure.ts
const terminalPunctuationRegex = /[.,!?]/g;
if (!terminalPunctuationRegex.test(newCaption.text)) {
return;
}
This wasn’t the end though, as there was another edge case: some captions already included ending punctuation before the caption was finalized. You can see this behavior in the example below which was a single caption that created two transcripts parts.
Gerry: I spent $500.00 today
Gerry: I spent $500.00 today at the store.
To avoid saving duplicates, I normalized both captions by stripping punctuation from both the new and last saved caption, then compared them. If they matched, I skipped it which was good enough for my use case.
//@title apps/teams-bot/src/procedures/captions-procedure.ts
const punctuationRegex = /[.,'"!~-?]/g;
const newCaptionText = newCaption.text.replace(punctuationRegex, '');
const latestCaptionText = this.state.captions[this.state.captions.length - 1]?.text.replace(punctuationRegex, '');
// Skipping caption event because it was the same as the latest caption
if (newCaptionText === latestCaptionText) {
return;
}
While this heuristic wasn’t perfect for all languages or styles (some captions don't end with punctuation), it significantly reduced spammy duplicates in meetings spoken in English.
For a more reliable build, you'll likely need a deeper integration with the Microsoft Teams API, either through their official Graph API or by intercepting caption events from the Microsoft Teams server.
By this point, I was confident that I had the finalized captions and could safely emit them to the notifier URLs.
Step 5: Emitting captions to the destination server
Compared to the hurdles of scraping and finalizing captions, sending finalized captions was straightforward. I wrapped the speaker's name, caption text, and a timestamp into a payload, then pushed it to each NOTIFIER_URLS endpoint in real time.
//@title apps/teams-bot/src/procedures/captions-procedure.ts
if (this.notifier) {
this.notifier.sendEventToServer({
payload: {
event: 'captions.data',
data: {
botId: this.state.botId,
captionFragment: newCaption
}
}
});
}
Hurray! This bot could now stream real-time captions from the meeting!
What it takes to make this bot scale
With that, I've shown you how to build a prototype bot for Microsoft Teams meetings to scrape captions. Scaling this to manage thousands of bots introduces new challenges though: orchestration, policy, UI changes, and the inherent difficulty of automating and maintaining the Microsoft Teams client. The focus shifts from caption extraction to maintaining hundreds of bots online, synchronized, and resilient against Microsoft Teams' complexities.
Here are some issues you'll encounter when running bots at scale.
Managing a fleet of bots
Building a bot is relatively straightforward - the challenge is managing thousands of concurrent bots.
Each bot involves:
-
On-demand Docker image deployments across multiple servers.
-
Precise scheduling to ensure timely arrival and transcription.
-
Continuous monitoring of health and resource usage across the fleet.
-
Robust handling of retries and replacements if a bot crashes mid-call.
This is like running a mini "serverless" platform, but with long-lived, stateful browser workloads.
Tracking Microsoft Teams meeting lifecycle states
Bots must accurately track their status within the Microsoft Teams meeting lifecycle (e.g., waiting room, lobby, in-call, captions enabled, captions flowing). Losing track of state means the bot might miss captions, wait to join meetings they’ve already entered, or fail to detect when a host removes the bot.
Accurate state handling requires:
-
Detecting transitions (join success, captions enabled/disabled, user kicked, failed to enter meeting).
-
Recovering gracefully if the state machine desyncs (e.g., Microsoft Teams UI didn’t render as expected).
-
Exposing states reliably to know if a bot is “healthy”.
Chasing Microsoft Teams’ UI rollouts
The Microsoft Teams web client lacks the stability of an API, as Microsoft often makes updates to the DOM. These changes, which can be gradual, A/B tested, or browser-dependent, will change selectors or layouts without notice. This can lead to broken bots until an engineer updates the bot's selectors to reflect the new DOM.
Handling Microsoft Teams failure modes
Even beyond Microsoft Teams client changes, there are failure modes outside my control. Some meetings don’t allow captions, and tenant or host policies can silently disable them. I’ve seen captions never appear or stop mid-call without warning. This leads to needing detection and fallback paths - surfacing issues to the host and triggering alerts, retries, or restarts when captions don’t appear within X seconds.
When a handful of bots isn’t enough
By now I’ve realized the real challenge isn’t scraping captions - it’s keeping fleets of bots resilient against Microsoft Teams’ quirks, policies, and crashes. Once you hit that wall, you have two options:
-
To build your own bot: keep investing in infrastructure, orchestration, and maintenance to chase Microsoft Teams’ UI and behavior changes.
-
To use a hosted meeting bot service: use a hosted solution like Recall.ai’s meeting bot API that has already solved these scale and reliability problems.
If you’re just experimenting, building your own bot makes sense. But for production-ready bots that need to scale, you should use hosted platforms like Recall.ai which are built to take on that burden. You can see a sample of how to do this in a few lines of code in the Appendix under Implement with Recall.ai.
Wrapping up this project
So here I am at the end of this project, having learned that building a Microsoft Teams bot to pull transcripts is deceptively complex. Beyond the different implementation paths, the real challenge was wrestling with the quirks of the Microsoft Teams meeting client. Getting the first prototype working felt like a huge win, but it didn’t take long to realize that was just the tip of the iceberg - the easy part was making it work once; the hard part was making it work reliably.
Key lessons I took away:
-
The Graph API had major limitations that made flexible, reliable bots hard to build.
-
Scraping captions with Playwright worked, but it’s inherently brittle.
-
If your goal is to learn, hacking together a bot is a great exercise. But if your goal is reliable, large-scale caption capture, you’ll find offloading your bot infrastructure as the better solution.
If you’re interested in production-ready bots, I recommend checking out Recall.ai’s meeting bot API. You can sign up and deploy your own meeting bots with a single API call, so you spend less time on infrastructure and more time building features your users actually care about.
Appendix
Summary of implementations evaluated
| Approach | Pros | Cons |
|---|---|---|
| Graph API | Officially supported, no DOM hacks, stable auth flow | High-friction flow requiring host permissions, no real-time transcript events |
| Brower Automations (Playwright) | Full control over captions as they appear, quick to prototype | Brittle (UI changes break selectors) |
Finalized implementation flow
Implement with Recall.ai
Below is a script on how to send a bot to a Microsoft Teams call and receive real-time transcripts through Recall.ai’s Microsoft Teams Meeting Bot API. This script includes the API call to the Recall.ai API and starts a simple express server to listen for real-time transcript webhooks
// @title index.js
// Fill in the following variables
const PORT = 3000;
const RECALL_API_TOKEN = 'RECALL_API_KEY';
const MICROSOFT_TEAMS_MEETING_URL = 'https://teams.microsoft.com/l/meetup-join/[...]'
const TRANSCRIPT_WEBHOOK_URL = 'https://your-ngrok-url.ngrok.io/webhook' // Ensure ngrok is pointing to the port defined above
// Recall.ai API Implementation
const createBot = async () => {
const response = await fetch(
'https://us-west-2.recall.ai/api/v1/bot',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Token ${RECALL_API_TOKEN}`
},
body: JSON.stringify({
meeting_url: MICROSOFT_TEAMS_MEETING_URL,
recording_config: {
transcript: {
provider: {
//Recommended Option: Recall Transcription (used meeting captions because of parity with the Microsoft Teams bot I built)
meeting_captions: {},
},
},
realtime_endpoints: [{
type: "webhook",
url: TRANSCRIPT_WEBHOOK_URL,
events: ["transcript.data"],
}],
}
})
}
)
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const bot = await response.json();
console.log(bot);
return bot;
}
createBot()
// Server Implementation
const express = require("express");
const app = express();
app.use(express.json());
app.post("/webhook", async (req, res) => {
try {
const { event, data } = req.body;
if (event === "transcript.data") {
const participant = data.data.participant.name;
const words = data.data.words;
// Log sentence words for participant
const sentence = words.map((word) => word.text).join(" ");
console.log(`${participant}: ${sentence}`);
}
res.status(200).json({ success: true, message: "Webhook received" });
} catch (error) {
console.error("Error processing webhook:", error);
res.status(500).json({ success: false, error: error.message });
}
});
app.listen(PORT, () => {
console.log(`Server running at http://localhost:${PORT}`);
});
Frequently Asked Questions
Is using Recall.ai's Meeting Bot API easier than building a meeting bot?
Recall.ai's Meeting Bot API is much easier than building a meeting bot yourself, but most crucially, it removes the maintenance and abstracts away the need to have separate integrations for separate platforms if your users live on more than just Microsoft Teams (e.g., Google Meet, Zoom, etc). If you are committed to building an open source Microsoft Teams bot, you can read out blog post on this topic.
Is there a Microsoft Teams transcript API?
Check out Recall.ai's Microsoft Teams Transcription API page to learn about the ways to get transcripts from a Microsoft Teams meeting. If you want step-by-step instructions on getting a transcript from Microsoft Teams, check out this guide on how to get a transcript from Microsoft Teams.
Is there a Microsoft Teams recording API?
Similarly, Recall.ai's Microsoft Teams Recording API page is where you can find information on accessing audio and video in real time from Microsoft Teams. This tutorial walks you through how to get recordings from Microsoft Teams.
How does joining a Microsoft Teams Meeting with Playwright compare to using Puppeteer?
Playwright and Puppeteer are similarly reliable for automating tasks like joining a Microsoft Teams meeting through the web client. Playwright’s built-in waiting, permission handling, and multi-browser support can make the join flow a bit smoother out of the box, while Puppeteer may require more manual waits or configuration to handle the same steps. In practice, both tools can achieve the same results. The choice mainly depends on your project’s setup and preferred automation style.
How can I build a Selenium Microsoft Teams bot to join meetings automatically?
Similar to how you'd build a bot to join a Microsoft Teams with Playwright or Puppeteer, you can build a Selenium Microsoft Teams bot by launching a browser with Selenium, opening the Microsoft Teams meeting URL, entering a display name, and clicking the “Join” button on the web client. From there, you can use waits to detect when the meeting has started or ended and handle pop-ups or permission prompts. Selenium can automate this reliably, though it may need a bit more setup for timing and permissions compared to Playwright or Puppeteer. You can also check out our blog on open source microsoft teams recording software.
How do I build a meeting bot using a meeting bot API?
Check out our blog on how to build a meeting bot to build a meeting bot using an API to get recordings and transcripts.
Can I build a bot for other meeting platforms?
If you're looking for a blog on how to use Recall.ai to build a meeting bot that works for Zoom, Google Meet, Microsoft Teams and more from scratch, the blog linked above on how to build a meeting bot is the easiest way to create a bot that will work for all of the major meeting platforms. You can also find blogs on how to build a Google Meet bot from scratch or Zoom bot from scratch. Even find ways to send a bot to Slack Huddles.
